AI Koçlukta Güven, Yanlılıkla Başlar ya da Biter
Integral yaklaşım açısından bakıldığında, yapay zeka destekli koçlukta değer üretme potansiyeli açıktır: kuruluşların %58’i Responsible AI girişimlerinin yatırım getirisini ve operasyonel verimliliği artırdığını söylüyor; ancak bu çerçeve uygulamaya inmediğinde güven ilk kırılan şey oluyor (PwC, 2025). AI koçlukta asıl soru artık “işe yarıyor mu?” değil; kime, hangi koşulda ve ne pahasına yarıyor?
Sorun burada sertleşiyor. Aynı araştırmada yöneticilerin %50’si, Responsible AI ilkelerini operasyonel süreçlere çevirmeyi en büyük engel olarak tanımlıyor (PwC, 2025). Bu, AI koçlukta etik riskin teorik değil, bütçe döneminde, performans görüşmesinde ve liderlik kararlarında doğrudan hissedilen bir uygulama açığı olduğunu gösterir. Bir bölge ölçeğinde hizmet şirketinde ekip direktörünün çeyrek dönem değerlendirmesinde AI destekli koçluk çıktısına dayanarak iki yöneticiyi “değişime kapalı” diye etiketlediğini düşünün; model teknik olarak çalışsa bile, o etiketin terfi, görev dağılımı ve ekip güveni üzerindeki etkisi haftalar içinde büyür. Bu yazı tam olarak bu kırılmanın nerede başladığını ve nasıl görünür kılınabileceğini açacak.
Yanlılık, çoğu kurumun sandığından daha geniş bir yüzeye yayılır. Sadece modelin verdiği öneride değil, modeli besleyen veride, o verinin nasıl yorumlandığında ve koçluk ilişkisinin nasıl kurulduğunda da oluşur. Bir çalışanın yazılı geri bildirim üretme alışkanlığı yüksekse sistem onu “yüksek öz-farkındalık” sinyali olarak okuyabilir; daha az yazan ama güçlü ilişki kuran bir başka çalışan ise görünmez kalabilir. Teknik hata yoktur belki. Ama değerlendirme yine de kaymıştır.

Yanlılık Neden Sadece Teknik Bir Problem Değildir?
İşte bu yüzden algoritmik yanlılık tartışmasını yalnızca veri bilimi ekibine bırakmak yetersizdir. Koçluk bağlamında yanlılık, üç katmanda birikir: veri seçimi, anlamlandırma, ilişkisel etki. Sistem hangi davranışı ölçülebilir sayıyorsa onu öne çıkarır; yönetici o çıktıyı hangi zihinsel çerçeveyle okuyorsa karar oraya kayar; çalışan da bu süreci ne kadar adil buluyorsa o kadar açık konuşur. Güven böyle kurulur ya da böyle çözülür.
Integral Bakışın Erken Uyarı Değeri
Integral yaklaşım, bu riski yalnızca birey düzeyinde değil; birey-ilişki-sistem-kültür eksenlerinde birlikte okumayı mümkün kılar. Bir öneri neden bir kişide savunma yaratıyor, neden bir ekipte sessizlik üretiyor, neden bir kurumda “objektiflik” diye kabul görüyor? Bu sorular, AI koçluk etiği için süslü bir ek değil, karar kalitesinin temelidir.
Değer gören oran %58 ise, uygulamaya takılan oran %50’dir; farkı belirleyen teknoloji değil, yargının nasıl yapılandırıldığıdır (PwC, 2025).
Asıl risk, AI koçluğun yanlış cevap vermesi değildir. Daha tehlikelisi, eksik bir okumayı tarafsızmış gibi sunmasıdır. Peki sistem neyi ölçer de güven verir, neyi kaçırır da ilişkiyi zedeler?
Yapay Zeka Koçlukta Neyi Ölçer, Neyi Kaçırır?
Yalnızca %19. Kurumlarda üretken yapay zekânın sorumlu kullanımını teşvik eden mekanizmaların bu kadar düşük kalması, günlük karar anlarında etik niyetin değil, ölçüm mantığının baskın olduğunu gösteriyor (World Economic Forum, 2025).
Aynı tabloda daha çarpıcı bir karşıtlık var: AI Governance Alliance ekosistemi 650’nin üzerinde küresel üyeye ulaşmış durumda (World Economic Forum, 2025). Yani yönetişim dili büyüyor; fakat koçluk oturumuna, performans konuşmasına ve yönetici yorumuna indiğimizde bu dil çoğu zaman davranışa dönüşmüyor.
Ölçebildiği Şey Güçlüdür, Ama Yeterli Değildir
Yapay zeka koçluk sistemleri örüntü yakalamada iyidir. Tekrarlayan ifade kalıplarını, geri bildirim sıklığını, hedef takibindeki sapmaları ve belirli davranış kümeleri arasındaki ilişkileri insandan daha hızlı tarayabilir. Bu, özellikle çok sayıda çalışanla çalışan kurumlarda erken sinyal üretmek için değerlidir.
Ama koçlukta asıl mesele sinyal üretmek değil, o sinyalin ne anlama geldiğini doğru tartmaktır. Bir yöneticinin kısa ve doğrudan yazması, düşük empati göstergesi olmayabilir; kriz döneminde zaman baskısıyla çalışan bir liderlik tarzı da olabilir. Sistem bunu işaret eder. Bağlamsal yargı ise hâlâ insanda kalmalıdır.
Bu yüzden insan denetimi bir güvenlik freni değil, yorum kalitesinin merkezidir.
Yanlılık Çıktıda Değil, Zincirin Tamamında Birikir
Yanlılık sıklıkla modelin verdiği son öneride aranır. Oysa sorun daha erken başlar: hangi verinin toplandığında, hangi davranışın “gelişim göstergesi” sayıldığında, prompt’un hangi varsayımla yazıldığında ve çıktının kim tarafından hangi amaçla yorumlandığında.
Bölgesel ölçekte bir sağlık kuruluşunda çeyrek dönem kadro planlaması yapılırken, birim müdürünün AI destekli koçluk özetlerini ekip dayanıklılığı göstergesi gibi kullandığını gözlemleyin. Sistemin daha çok yazılı geri bildirim bırakan çalışanları “yüksek katılım” olarak öne çıkarması, sahada çalışan ve daha az dijital iz bırakan deneyimli ekip üyelerini geri plana iter. Teknik olarak tutarlı görünen çıktı, uygulamada adaletsiz bir görünürlük rejimi üretir.
Fark tam burada oluşur.
İnsan Merkezli Koçluk ile AI Destekli Değerlendirme Aynı Şey Değildir
İnsan merkezli AI koçluk, kişinin düşünmesini derinleştiren bir destek katmanıdır. AI destekli değerlendirme ise kişiyi sınıflandırmaya, sıralamaya veya karar nesnesine dönüştürme riski taşır. Etik sınır da burada çizilir: sistem, içgörü mü üretiyor; yoksa hüküm mü veriyor?
World Economic Forum verisindeki %19’luk teşvik açığı bu nedenle önemlidir (World Economic Forum, 2025). Kurumlar sorumlu kullanımı ödüllendirmediğinde, araçlar doğal olarak hız, standardizasyon ve raporlanabilirlik için kullanılır; koçluk ise sessizce değerlendirmeye kayar.
Sorulması gereken soru teknik değildir. Sistem gelişimi mi destekliyor, yoksa kişiyi indirgenmiş bir profile mi sıkıştırıyor — ve bu ayrımı hangi çerçeveyle yapıyoruz?
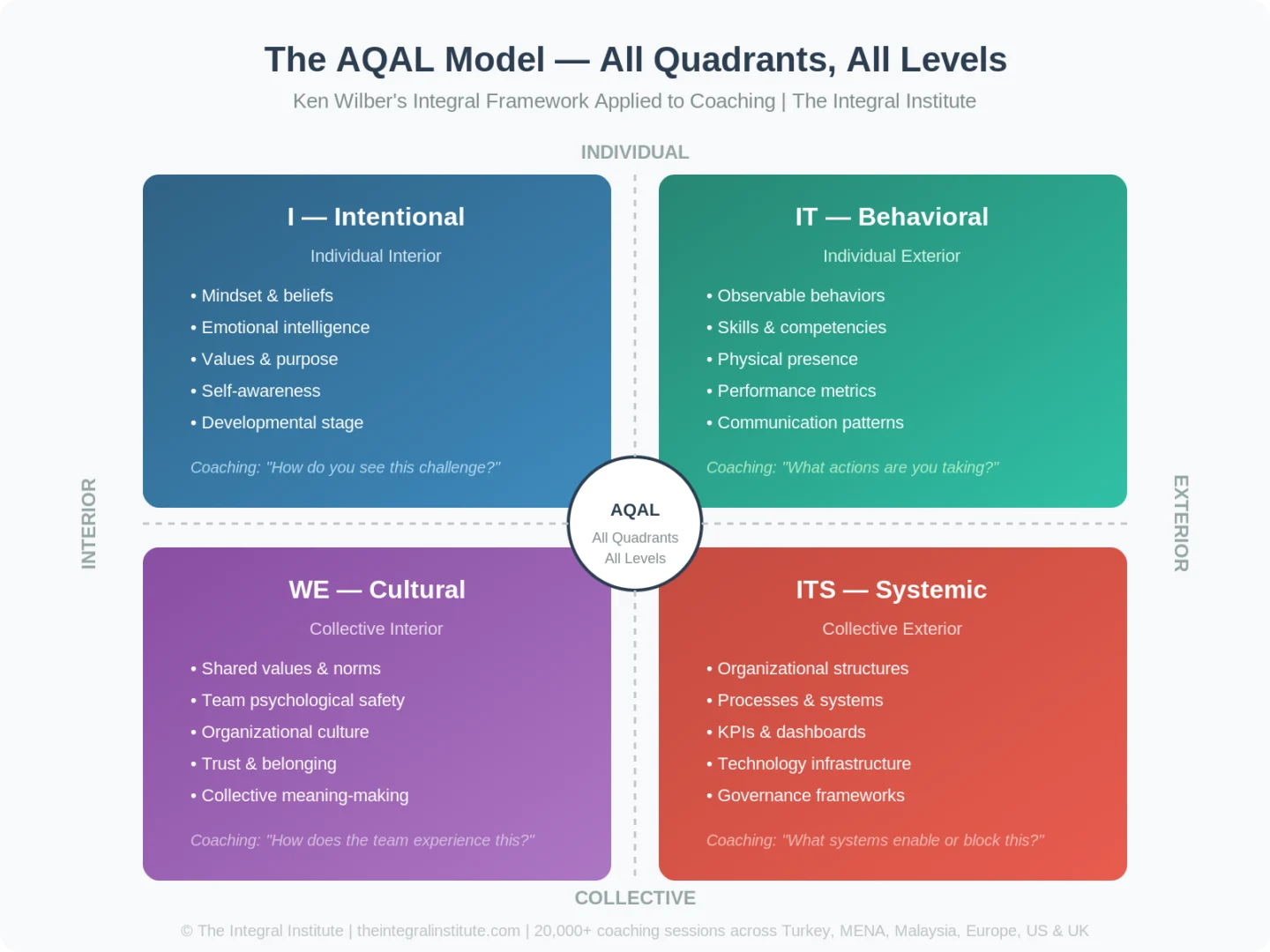
Integral Teori AI Etiğine Nasıl Bir Harita Sunar?
AQAL çerçevesi, tam da burada önemlidir: Evrensel etik ilkeler varsa, bunlar koçluk pratiğinde hangi karar anına nasıl iner? Birçok ekip, etik riskin bir politika metniyle yönetilebileceğini varsayar. Oysa asıl kırılma, ilkenin doğru olması değil, sahadaki karmaşık insan durumlarını taşıyıp taşıyamamasıdır.
UNESCO’nun Yapay Zekâ Etiği Tavsiye Kararının Kasım 2021’de kabul edilmesi ve 194 üye devlet için geçerli olması, kurumlara güçlü bir normatif zemin sunuyor (UNESCO, 2021). Fakat normun varlığı, yorumun adil olacağını garanti etmez. İşte Integral teori burada soyut bir felsefe değil, etik riski haritalayan pratik bir okuma çerçevesi hâline gelir.
Dört Düzeyi Aynı Anda Görmek
Integral teori, AI destekli koçlukta riski tek bir noktada aramaz; birey, ilişki, ekip/sistem ve kültür düzeylerini birlikte okur. Bir çalışanın AI çıktısına neden savunmayla yaklaştığı bireysel bir mesele gibi görünebilir; ancak yöneticinin bunu nasıl sunduğu ilişkisel katmanı, çıktının hangi süreçte kullanıldığı sistem katmanını, “veri söylüyorsa doğrudur” inancı ise kültürel katmanı açığa çıkarır.
Bu ayrım pratiktir. Bölgesel ölçekte bir üretim şirketinde çeyrek dönem yeniden yapılanması sırasında operasyon direktörünün AI destekli koçluk özetlerini liderlik potansiyeli tartışmasına taşıdığını canlandırın. Bir yönetici için “düşük etki alanı” yorumu üretildiğinde sorun yalnızca kişinin profili değildir; bu yorumun toplantıda kesin hüküm gibi okunması, ekipte itirazın zayıflaması ve kurum kültüründe ölçülebilir olanın tek gerçek sayılmasıdır. AQAL mantığı, riski çıktıda değil, kararın dolaştığı bağlamda görmeyi sağlar.

Amaç Doğrulamak Değil, Kör Noktayı Bulmaktır
Buradaki kritik nokta şudur: çoklu perspektif yaklaşımı, AI’nin söylediğini onaylamak için kullanılmamalıdır. Asıl işlevi, AI’nin göremediğini görünür kılmaktır.
Bir model, dil kalıplarından kararsızlık çıkarabilir. Fakat aynı ifade, bazı ekiplerde dikkatli liderlik davranışı olarak da okunur. Bir çalışan sessiz görünüyorsa bu düşük katılım değil, cezalandırıcı toplantı kültürüne verilmiş rasyonel bir tepki olabilir. etik AI tasarımı bu yüzden yalnızca doğruluk meselesi değildir; hangi perspektifin sistematik olarak dışarıda kaldığını sorma disiplinidir.
UNESCO’nun 194 üye devleti kapsayan etik çerçevesi, kurumlara “neye dikkat etmeliyiz?” sorusunun zeminini verir; Integral yaklaşım ise “bunu karar anında nasıl okuyacağız?” sorusunu çalıştırır (UNESCO, 2021).
Tek Cevap Değil, Daha Adil Yargı
Koçlukta en güvenli kararlar, tek doğru cevaptan değil, çoklu bakış açısından çıkar. Çünkü insan gelişimi doğrusal değildir; bağlam, rol, güç ilişkisi ve kurum dili aynı davranışı farklı anlamlara taşıyabilir. Bu nedenle iyi bir AI koçluk sistemi, kesinlik üretmekten çok yargıyı yavaşlatmalı; sınıflandırmaktan çok soru açmalıdır.
Sorun artık ilke eksikliği değildir. Asıl sorun, bu ilkeleri günlük kararlara kimlerin, hangi disiplinle ve ne kadar tutarlılıkla çevirebildiğidir — sistem mi konuşuyor, yoksa sadece sistemin diliyle insanlar mı hüküm veriyor?
Neden Çoğu Organizasyon Etik İlkeleri Uygulamaya Dönüştüremiyor?
%61. Kurumların yaklaşık altıda onu Responsible AI açısından kendini stratejik ya da gömülü aşamada görüyor; buna rağmen günlük karar anlarında güven aşınıyor, yetenek kaybı hızlanıyor ve yanlış etiketlenen çalışanların bedeli doğrudan performansa yazılıyor (PwC, 2025). Strateji seviyesinde görünen olgunluk neden günlük koçluk kararlarında kayboluyor? Çünkü sorun büyük ölçüde ilke eksikliği değil, işletim tasarımı eksikliğidir.
Politika Var, Karar Akışı Yok
McKinsey’nin ortalama 2,0/4 Responsible AI olgunluk skoru, kurumların ne başlangıçta ne de gerçek anlamda yerleşik bir düzende olduğunu gösteriyor (McKinsey, 2025). Daha çarpıcısı, katılımcıların yalnızca yaklaşık %36’sı Seviye 2’de; yani birçok organizasyon temel yapı taşlarını kurmuş olsa da bunları tutarlı karar mekanizmalarına çevirebilmiş değil (McKinsey, 2025).
Bu fark koçlukta çok görünürdür. İlke metninde “insan denetimi” yazmak kolaydır; fakat çeyrek dönem performans kalibrasyonunda AI özetini kimin okuyacağı, hangi yorumun kayıt altına alınacağı, itirazın hangi eşikte zorunlu olacağı tanımlanmadığında, sistem fiilen hüküm üretmeye başlar. Etik burada soyut bir değer değil, karar akışının mimarisidir.
Bir orta ölçekli teknoloji şirketinde ürün direktörünün bütçe daralması sırasında AI destekli koçluk çıktılarından hareketle üç takım liderini “değişime uyum riski” başlığı altında gruplayıp yeniden yapılanma listesine taşıdığını şunu fark edin. Sorun modelin tek başına yanılması değildir; o çıktının hangi bağlamda üretildiği, kim tarafından sorgulanmadan kabul edildiği ve çalışanın buna nasıl itiraz edeceğinin tasarlanmamış olmasıdır. Bir haftada alınan kararın güven maliyeti aylar sürer.
Yanlılığı Azaltmak, Süreci Yeniden Kurmaktır
Tam bu nedenle yanlılık azaltma, yalnızca algoritmik yanlılık için bir politika yazmak değildir. Veri girişi, yorumlama, eskalasyon, itiraz, kayıt ve geri bildirim döngülerinin yeniden tasarlanması gerekir. Hangi çıktı koçluk içgörüsü olarak kalacak, hangisi yönetsel karara hiç girmeyecek, hangisi ikinci bir insan değerlendirmesi olmadan kullanılamayacak — bunlar netleşmeden etik uygulamaya inmez.
Kurumlar genellikle uyum mantığıyla hareket eder: bir komite kurulur, birkaç ilke yayımlanır, risk maddeleri listelenir. Oysa koçluk bağlamında etik, önce ilişkisel güveni korumalıdır. Çalışan sistemin kendisini anlamaya mı çalıştığını hissediyor, yoksa sessizce sınıflandırdığını mı? Tasarım sorusu budur.
Ortalama olgunluk skoru 2,0/4 iken ve yalnızca yaklaşık %36 Seviye 2’deyken, asıl açık niyette değil uygulama disiplinindedir (McKinsey, 2025).
PwC’nin gösterdiği %61’lik stratejik görünüm ile sahadaki kırılma arasındaki mesafe, tam da bu nedenle büyür (PwC, 2025). Peki hangi kararlar o kadar yüksek etki taşır ki, iyi tasarlanmış süreçler olsa bile tam otomasyona bırakılmamalıdır — öneri mi, yoksa hüküm mü?
AI Koçlukta Hangi Kararlar Asla Tam Otomasyona Bırakılmamalı?
Bir bölgesel lider perakende şirketinde çeyrek dönem değerlendirmesi kapanırken, mağaza operasyonlarından sorumlu direktörün önüne AI destekli koçluk özetleri düşer; sistem iki mağaza müdürünü “savunmacı iletişim” riskiyle işaretlemiştir. O anda verilen karar teknik görünür, ama aslında ilişkiseldir: bu çıktı gelişim konuşmasına mı girecek, performans dosyasına mı, yoksa hiç kullanılmayacak mıdır?
Gallup’a göre çalışanların yalnızca %23’ü kurum liderliğine güçlü biçimde güvendiğini söylüyor; bağlılık oranı ise 2024’te %31 ile son on yılın en düşük seviyesine inmiş durumda (Gallup, 2024). Güvenin ve bağlılığın bu kadar zayıf olduğu bir zeminde, AI’nin ürettiği bir öneri kolayca “tarafsız içgörü” gibi okunur. Oysa koçlukta en riskli an tam burasıdır: sistemin söylediği şeyin ne olduğu kadar, insanın onu nasıl kullandığı belirleyicidir.
Onam ve Sınır Koyma Otomatikleştirilemez
Onam, gizlilik, sınır koyma ve hassas geri bildirim, prosedür değil yargı meselesidir. Bir çalışanın koçluk oturumunda paylaştığı kırılgan bir konunun hangi koşulda kayda geçeceği, hangi dilin güveni koruyacağı ve hangi bilginin yönetsel karara hiç taşınmaması gerektiği, önceden yazılmış kurallarla tam çözülemez.
İşte bu noktada AI koçluk etiği yalnızca “izin alındı mı?” sorusuna indirgenmemelidir. Asıl soru şudur: kişi gerçekten neye onay verdiğini anladı mı, bu onayın kapsamı değiştiğinde yeniden bilgilendirildi mi, geri çekilme hakkı pratikte de var mı?

AI Önerir, İnsan Anlamlandırır
AI, örüntü gösterir. Koç ise anlam kurar, bağlamı tartar ve etik sorumluluğu taşır. Bir finans girişiminde ekip liderinin yazılı ifadelerinden “düşük dayanıklılık” sinyali çıkması, yeniden yapılanma baskısı altındaki bir dönemde gayet anlaşılır bir tepki de olabilir. Sistemin görevi bunu işaretlemektir; hüküm vermek değil.
Burada insan denetimi son aşamadaki bir imza süreci değildir. Tasarımda başlar — hangi verinin alınacağı, hangi çıktının koçluk alanında kalacağı, hangi durumda ikinci bir insan değerlendirmesinin zorunlu olacağı en baştan belirlenir. Sonra kullanımda sürer — koç, yöneticinin aceleci yorumunu yavaşlatır; çalışan için güvenli sınırı korur.
Güvenin yalnızca %23, bağlılığın ise %31 olduğu bir ortamda, tam otomasyon hız kazandırabilir; ama yanlış okunan tek bir çıktı aylarca onarılamayan ilişki hasarı yaratabilir (Gallup, 2024).
Asla tamamen otomasyona bırakılmaması gereken kararlar, etkisi veri tablosunu aşan kararlardır. Peki kurumlar bu sınırı nereden çizecek — ilke metninden mi, yoksa günlük iş akışının içinden mi?
Yanlılığı Azaltmak İçin Nereden Başlamalı?
Bias haritalama çerçevesi ile başlamak gerekir; çünkü yönetişim ağları 650’nin üzerine çıkmış olsa da günlük kullanımda doğru davranışı teşvik eden mekanizmalar yalnızca %19 düzeyinde kalıyorsa, sorun ilke eksikliğinden çok uygulama kırılmasındadır (World Economic Forum, 2025). Bu çerçeve kurulmadığında bozulan şey model değil, karar zinciridir: veri masum görünür, prompt nötr sanılır, yorum ise “objektif” diye dolaşıma girer.
Yanlılık Tek Noktada Değil, Katmanlarda Oluşur
İlk pratik adım, yanlılığın nerede üretildiğini beş ayrı katmanda çıkarmaktır: veri, model, prompt, yorum ve uygulama. Veri katmanında hangi davranışların iz bıraktığına bakılır; model katmanında hangi örüntülerin aşırı ağırlık kazandığına; prompt katmanında sorunun hangi varsayımla sorulduğuna; yorum katmanında yöneticinin hangi zihinsel kısayolla sonuca atladığına; uygulama katmanında ise çıktının koçluk içgörüsünden yönetsel hükme nerede dönüştüğüne.
Bu ayrım teorik değildir. Çeyrek dönem kapanışında orta ölçekli bir hizmet şirketinin insan kaynakları direktörü, AI destekli koçluk özetlerini lider havuzu değerlendirmesine taşırken, sistemin “düşük görünürlük” diye işaretlediği iki yönetici aslında müşteri sahasında çalışan ve yazılı iz bırakmayan kişiler olabilir. Burada sorun yalnızca algoritmik yanlılık değildir; görünürlük ile potansiyelin birbirine karıştırılmasıdır.
Küçük bir harita, büyük bir fark yaratır.
Her Rol İçin Ayrı Kontrol Noktası Gerekir
Koç, yönetici ve organizasyon aynı riski farklı yerde üretir; bu yüzden kontrol noktaları da ayrı tasarlanmalıdır. Koç için temel soru, çıktının kişiyi açıp açmadığıdır — savunma yaratıyorsa dil yeniden kurulmalıdır. Yönetici için eşik daha serttir: AI çıktısı tek başına performans, terfi ya da yeniden yapılanma kararına giremez. Organizasyon içinse asıl kontrol, eskalasyon mantığıdır; hangi durumda ikinci insan değerlendirmesi zorunlu olacak, hangi durumda kayıt tutulacak, hangi durumda çıktı hiç kullanılmayacaktır?
World Economic Forum’un gösterdiği çelişki tam burada önem kazanır: 650’yi aşan küresel yönetişim ağına rağmen sorumlu GenAI kullanımını teşvik eden yapıların %19’da kalması, kurumların “neye inanıyoruz?” sorusunu yanıtladığını, ama “kim nerede duracak?” sorusunu hâlâ açık bıraktığını gösteriyor (World Economic Forum, 2025). Etik AI pratikte tam da bu rol netliğiyle başlar.
Büyük Düzeltme Değil, Düzenli Etik Kontrol
En etkili başlangıç, yılda bir yapılan ağır denetim değildir. Haftalık örnek çıktı incelemesi, aylık itiraz kaydı taraması ve belirlenmiş bir eskalasyon eşiği — örneğin yüksek etkili kararlarda zorunlu ikinci okuma — birçok noktada geç gelen büyük düzeltmelerden daha fazla koruma sağlar.
Çünkü yanlılık bir anda patlamaz; sessizce normalleşir. Kurum bunu erken mi fark edecek, yoksa güven kaybı olduktan sonra mı ölçmeye çalışacak?
Etik AI Koçlukta Asıl Başarı, Daha Az Otomasyon Değil Daha İyi Yargıdır
Yargı kalitesi çerçevesi, bu tartışmada neden belirleyicidir? Çünkü yanlış kurulan bir AI koçluk düzeni önce güveni aşındırır, sonra iyi insanları sessizce uzaklaştırır, en sonunda da hatalı kararların maliyetini performans kaybı olarak kuruma geri yazar.
Bir kurumsal hizmetler şirketinde yıllık bütçe daralmasının ortasında, bölüm başkanının AI destekli koçluk özetlerini ekip yeniden yapılanmasına dayanak yaptığını bir an için düşleyin; birkaç hafta içinde iki güçlü yönetici kurumdan ayrıldığında, kayıp yalnızca yetenek değildir. Ekipte kalanların konuşma cesareti de düşer. Etik hata, burada teknik bir kusur gibi değil, ilişki sermayesinin erimesi gibi görünür.
Evrensel ilke varsa, olgunluk nasıl görünür?
UNESCO’nun Yapay Zekâ Etiği Tavsiye Kararının 2021’de kabul edilmesi ve 194 üye devlet için geçerli olması önemli bir çıpa sağlar: kurumlar artık etik zeminin ne kadar geniş ve ortak olduğunu inkâr edemez (UNESCO, 2021). Ama evrensel ilke tek başına olgunluk üretmez. Gerçek olgunluk, ilkenin karar anında nasıl taşındığında ortaya çıkar.
Burada başarı ölçütü de değişmelidir. AI koçlukta iyi sonuç, daha hızlı özet üretmek ya da daha çok davranışı sınıflandırmak değildir; güveni, adaleti ve kararın açıklanabilirliğini koruyabilmektir. Bir çıktı çok hızlı gelebilir. Eğer kişi o çıktının nasıl üretildiğini anlamıyor, nerede kullanılacağını bilmiyor ve itiraz edemiyorsa, sistem verimli görünse bile etik olarak zayıftır.
Kısacası mesele otomasyon seviyesi değildir. Mesele, kararın taşıdığı insan etkisidir.
Integral yaklaşım neden uzun vadede daha sağlamdır?
Integral yaklaşım, tek bir doğru cevap aramak yerine bir kararın birden fazla düzeyde ne ürettiğine bakmayı öğretir: kişi üzerinde ne etkisi var, ilişkiyi nasıl değiştiriyor, ekipte hangi davranışı normalleştiriyor, kurum kültüründe neyi görünmez kılıyor? Dolayısıyla Integral teori yalnızca kavramsal bir çerçeve değil, yargıyı daraltan kısayollara karşı bir disiplin işlevi görür.
Bu disiplin özellikle kapanış anlarında değerlidir. Yönetici “sistem böyle söylüyor” diyerek rahatlamak ister. Koç ise daha zor olanı yapmalıdır: soruyu yeniden açmak, bağlamı geri getirmek, kesin görünen yorumu yavaşlatmak. AI koçluk etiği tam burada canlıdır — politika metninde değil, hükmü geciktirebilen pratikte.
UNESCO’nun 194 üye devleti kapsayan etik zemini, ortak yönü gösterir; kalıcı farkı ise kurumun kendi yargı standardı yaratması belirler (UNESCO, 2021).
Kalıcı çözüm, teknolojiye daha fazla yetki vermek değildir. İnsan yargısını daha net, daha şeffaf ve daha sorumlu hâle getirmektir.
Kendi bağlamınıza dönüp bakın: sizde AI koçluk çıktıları düşünmeyi mi derinleştiriyor, yoksa karar vermeyi mi kolaylaştırıyor? Eğer ikincisi ağır basıyorsa, belki de bir sonraki adım yeni araç aramak değil, mevcut yargı disiplinini yeniden kurmaktır.
Öne Çıkanlar
- AI koçlukta güven, yanlılığın nerede başladığı ve nasıl yönetildiğiyle doğrudan bağlantılıdır.
- Yanlılık yalnızca modelde değil; veri, yorum ve uygulama zincirinin tamamında birikir.
- Integral yaklaşım, etik riski birey, ilişki, sistem ve kültür düzeylerinde birlikte okumayı sağlar.
- Tam otomasyona bırakılmaması gereken kararlar, insan yargısı ve insan denetimi gerektirir.
Sıkça Sorulan Sorular (SSS)
Yapay zeka destekli integral koçlukta yanlılık neden sadece teknik bir sorun değildir?
Çünkü yanlılık yalnızca modelin çıktısında değil, verinin seçilmesinde, çıktının nasıl yorumlandığında ve koçluk ilişkisinin nasıl kurulduğunda da oluşur. Bu nedenle adalet, teknik doğruluktan çok daha geniş bir karar zincirini kapsar.
Integral yaklaşım yapay zeka koçlukta etik riskleri nasıl görünür kılar?
Integral yaklaşım, riski birey, ilişki, sistem ve kültür düzeylerinde birlikte değerlendirir. Böylece bir çıktının neden savunma yarattığı, sessizlik ürettiği veya kurum içinde tarafsız sanıldığı daha net anlaşılır.
Yapay zeka koçlukta hangi kararlar tam otomasyona bırakılmamalıdır?
Onam, gizlilik, sınır koyma, hassas geri bildirim ve performans ya da terfi gibi yüksek etkili kararlar tam otomasyona bırakılmamalıdır. Bu tür kararlar bağlam, güç ilişkisi ve insan yargısı gerektirir.
Yanlılığı azaltmak için kurumlar nereden başlamalıdır?
En etkili başlangıç, yanlılığın veri, model, prompt, yorum ve uygulama katmanlarında nerede oluştuğunu haritalamaktır. Ardından ikinci insan değerlendirmesi, itiraz mekanizması ve düzenli çıktı incelemesi gibi kontrol noktaları kurulmalıdır.
Etik yapay zeka koçlukta başarı nasıl ölçülmelidir?
Başarı, daha fazla otomasyon veya daha hızlı özet üretimiyle değil, güvenin, adaletin ve açıklanabilirliğin korunmasıyla ölçülmelidir. Sistem kişinin düşünmesini derinleştiriyor ve karar kalitesini artırıyorsa etiktir; kişiyi indirgenmiş bir profile sıkıştırıyorsa risklidir.